计算机与人工智能学院有2篇论文被国际顶级会议——第29届国际多媒体学术会议(ACM International Conference on Multimedia, 简称ACM MM)录用。这两篇论文均是以西南交通大学为第一署名单位。在全球1942篇投稿中,542篇论文被录用,接收率为27.9%。国际多媒体学术会议(ACM MM)是计算机学科公认的多媒体领域和计算机视觉领域的国际顶级会议,被中国计算机学会(CCF)列为A类会议,在我校期刊分级目录中列为A++级别。在教育部第四轮学科评估中,CCF A类会议论文被列为重要的论文发表指标项。这是我校计算机学科自2016年以来,连续六年在ACM MM发表高水平论文,标志着我校在人工智能和计算机视觉领域的研究成果得到了国际同行的认可。
车辆目标计数是当前计算机视觉领域的前沿研究之一,由于受尺度变化、位置分布不一致、视觉表观多样化等多种因素影响,该任务极具挑战性。计算机与人工智能学院博士生张基为第一作者,吴晓教授为通讯作者,博士生乔建军和李威老师共同完成的论文《Vehicle Counting Network with Attention-based Mask Refinement and Spatial-awareness Block Loss》提出了一种基于细粒度注意力掩码和空间感知损失的车辆计数网络(VCNet)来解决所述难点。论文采用了多分支混合空洞卷积块结构,生成包含不同尺度信息的高质量密度图。同时,设计了一种能够感知不同位置空间分布的损失函数来提高模型的空间感知能力。该方法在多个公开车辆计数数据集上取得了最优的计数结果,有效缓解了拥挤交通场景中车辆尺度、视觉信息变化剧烈和空间分布不一致的难题。
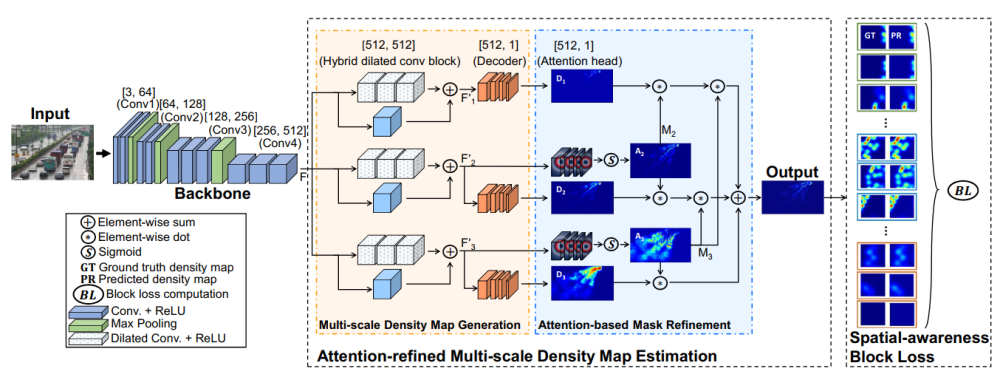
图表 1 基于细粒度注意力掩码和空间感知损失的车辆计数网络架构图
视觉问答系统是视觉-语言结合的研究热点之一。计算机与人工智能学院袁召全老师为第一作者,吴晓教授为通讯作者,硕士生彭潇以及我校兼职教授徐常胜共同完成的论文《Hierarchical Multi-Task Learning for Diagram Question Answering with Multi-Modal Transformer》提出了一种新颖的基于多模态Transformer框架的层级多任务学习(HMTL)模型。相对于自然图片的问答,插图问答(Diagram QA)任务需要对视觉插图和文本问答语句进行联合的语义理解与推理,是一项具有挑战性的研究课题。现有的独立两阶段方法受限于低效率的反馈机制而不能实现端到端的参数学习。在提出的HMTL中,图结构化解析和问答这两个任务采用不同的Transformer模块,并处于不同的语义层级,从而形成层次结构。结构解析模块对插图中的成分及其关系进行编码,问答模块则对结构化信号进行解码并结合问答语句来推断正确的答案。视觉的图解析与文本问答在多模态Transformer中相互作用,从而实现跨模态的语义理解和推理。实验证明,论文提出的HMTL模型对插图问答任务具有有效性,并在公开数据集上达到当前最优性能。
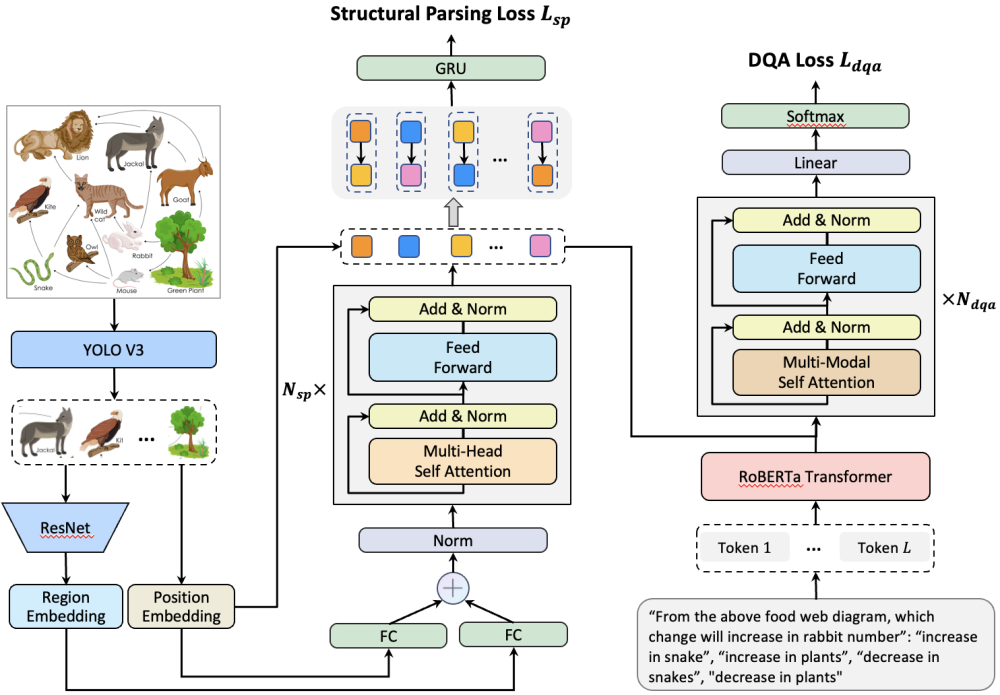
图表 2 基于层级多任务学习的图表问答系统架构图
计算机与人工智能学院在计算机领域国际会议的连续突破,反映出学院在“智能引领、交叉融合”的战略牵引下,在科研创新、扩大国际影响力、开拓国际视野等方面取得了重要进展。












